

Nella continua evoluzione dell’intelligenza artificiale (IA), i modelli linguistici di grandi dimensioni (LLM) come ChatGPT e Gemini hanno raggiunto livelli impressionanti di capacità nel comprendere e generare linguaggio naturale. Tuttavia, lungo il cammino verso l’assimilazione di una conoscenza vasta e l’elaborazione di risposte coerenti, questi stessi modelli sono suscettibili di produrre allucinazioni linguistiche, dove il contenuto generato è erroneo, impreciso o completamente insensato. Questo fenomeno rappresenta una sfida significativa per la fiducia e l’affidabilità degli LLM, specialmente in contesti dove la precisione è critica.
Il problema delle allucinazioni nei LLM
Le allucinazioni nei LLM derivano spesso da lacune nella loro conoscenza o da interpretazioni errate del contesto. Questo può portare a risposte che, pur sembrando plausibili superficialmente, non resistono a un’analisi più approfondita o che sono inconsistenti con fatti noti. Ad esempio, un LLM potrebbe generare risposte che sembrano coerenti in base alle regole grammaticali e al contesto sintattico, ma che sono semanticamente scorrette o prive di evidenza empirica.
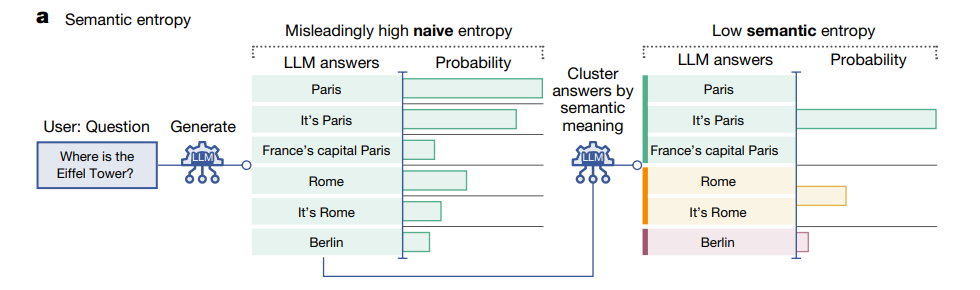
Il rilevamento di queste allucinazioni è un compito complesso, in quanto richiede non solo la capacità di identificare risposte errate, ma anche di comprendere la natura delle distorsioni semantiche che possono verificarsi a causa della mancanza di dati o di una comprensione incompleta del contesto di riferimento.
Rilevare le “confabulazioni”
Il recente studio pubblicato su Nature introduce un metodo innovativo per rilevare e quantificare le allucinazioni nei LLM, concentrandosi in particolare su una categoria specifica chiamata confabulazioni. Le confabulazioni si manifestano quando un LLM genera risposte che sono arbitrarie, imprecise o senza una base solida di conoscenza. Questo fenomeno è particolarmente evidente in ambiti in cui il modello deve elaborare informazioni su argomenti complessi o meno strutturati, come biografie o domande aperte su scienze e cultura generale. Le confabulazioni possono essere il risultato di un processo di generazione del linguaggio che cerca di compilare informazioni mancanti o di creare una narrazione coerente sulla base di dati limitati o errati.
Rendere più efficaci i modelli linguistici di grandi dimensioni
Il metodo sviluppato da Sebastian Farquhar e il suo team si avvale di una serie di tecniche avanzate per misurare l’incertezza nel significato delle risposte prodotte dagli LLM. Questo include l’analisi delle variazioni semantiche e la sottigliezza del linguaggio utilizzato nei contenuti generati. Inoltre, il metodo impiega un secondo LLM per valutare le risposte, creando così un sistema di “controvalutazione” che mira a identificare discrepanze e incoerenze nel materiale prodotto. Questa approccio di valutazione incrociata è fondamentale per migliorare l’affidabilità delle risposte degli LLM, consentendo di confrontare le interpretazioni del linguaggio e di identificare le aree di incertezza o di possibile errore.
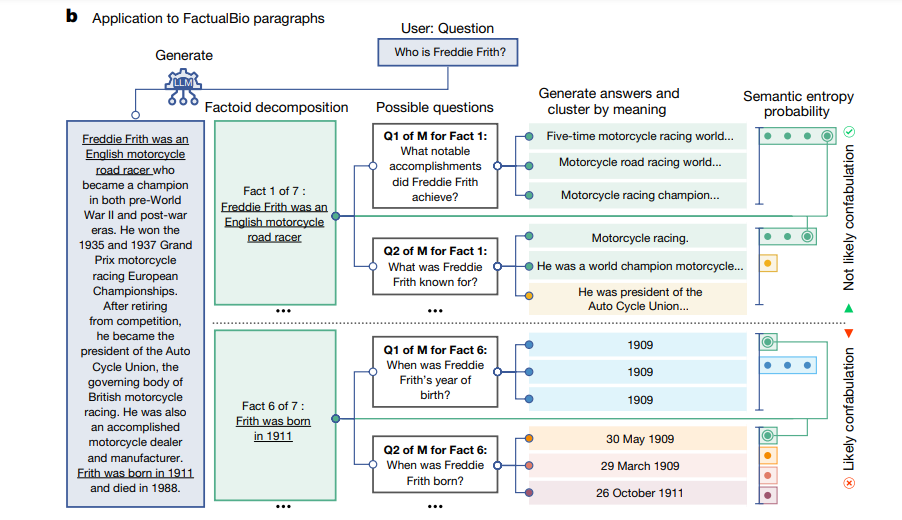
L’uso di un LLM per valutare un altro LLM solleva questioni etiche e metodologiche complesse. Karin Verspoor ha sottolineato il rischio di parzialità implicita in questo tipo di approccio, suggerendo che potrebbe creare un circolo vizioso di validazione in cui gli errori o le allucinazioni possono essere perpetuati senza una vera correzione esterna. Tuttavia, gli autori dell’articolo suggeriscono che questa metodologia potrebbe migliorare la sicurezza e l’affidabilità nell’uso degli LLM, rendendo più chiaro quando le risposte generate possono essere considerate accurate e quando invece dovrebbero essere trattate con cautela. Inoltre, l’approccio proposto potrebbe essere implementato con meccanismi di feedback e correzione automatica, contribuendo così a un miglioramento continuo della qualità delle risposte degli LLM nel tempo.
Potenziali applicazioni della scoperta
Il contributo di Farquhar et al. rappresenta un passo significativo verso la creazione di LLM più affidabili e trasparenti. Oltre a migliorare la qualità delle risposte, questo approccio potrebbe avere un impatto positivo su una vasta gamma di settori, inclusi la ricerca scientifica, l’assistenza sanitaria, l’educazione e molto altro ancora. La capacità di mitigare le allucinazioni nei modelli di linguaggio potrebbe aprire la strada a un utilizzo più sicuro e responsabile dell’IA, consentendo di sfruttare appieno il potenziale di queste tecnologie emergenti senza compromettere l’integrità delle informazioni fornite. Ad esempio, nei contesti clinici, dove la precisione e l’accuratezza delle informazioni sono cruciali per le decisioni diagnostico-terapeutiche, l’adozione di LLM più robusti e accuratamente validati potrebbe migliorare significativamente la qualità delle cure fornite ai pazienti.
