
Negli ultimi anni, l’intelligenza artificiale (IA) ha compiuto passi da gigante, influenzando in profondità numerosi settori della nostra vita quotidiana. Tra le innovazioni più significative si trovano i modelli di apprendimento automatico, noti come modelli di linguaggio, che hanno rivoluzionato il modo in cui interagiamo con la tecnologia. Questi strumenti, che utilizzano algoritmi avanzati per analizzare e generare testo, hanno trovato applicazioni in una vasta gamma di ambiti, dal servizio clienti alla produzione di contenuti fino alla traduzione automatica.
Tuttavia, un recente studio pubblicato su Nature solleva preoccupazioni critiche riguardo all’uso di dataset generati da IA per addestrare le successive generazioni di modelli, mettendo in luce un problema che potrebbe minacciare l’efficacia e la qualità dei sistemi di IA: il fenomeno noto come “model collapse” o collasso del modello. Questo problema potrebbe avere ripercussioni significative sull’affidabilità dei modelli di IA e sulla loro capacità di fornire risultati utili e accurati, influenzando così la nostra fiducia e dipendenza da tali tecnologie.
L’ascesa dei modelli di linguaggio
Gli strumenti di IA generativa, in particolare i grandi modelli di linguaggio (LLM), sono diventati sempre più popolari grazie alla loro capacità di produrre testi coerenti e sofisticati a partire da input umani. Questi modelli, come GPT-4, sono addestrati su enormi volumi di dati provenienti da fonti umane, che permettono loro di comprendere e generare linguaggio naturale con notevole precisione. L’aumento della capacità di questi modelli di generare risposte pertinenti e contestualmente appropriate ha portato a un ampio utilizzo in settori quali il supporto clienti automatizzato, la creazione di contenuti editoriali e la sintesi di informazioni complesse.
Tuttavia, con la crescente diffusione di questi strumenti, si è iniziato a fare un uso sempre più ampio dei contenuti generati da computer per addestrare ulteriori modelli di IA. Questo processo crea un ciclo ricorsivo in cui i modelli si allenano su output che sono a loro volta il risultato di altri modelli di IA. Questo ciclo potrebbe comportare rischi inattesi, poiché i contenuti prodotti dai modelli stessi possono riflettere e amplificare gli errori o le distorsioni presenti nei dati di origine, portando a un’erosione della qualità complessiva dei modelli di IA.
Il “model collapse”
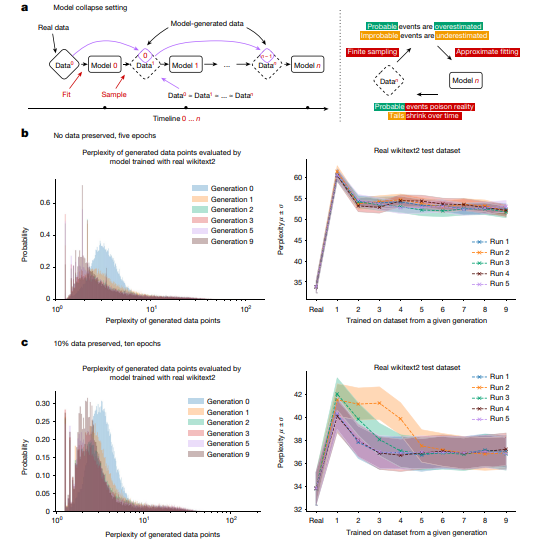
Il termine “model collapse” si riferisce a una situazione in cui i modelli di IA, addestrati su dati generati da IA, cominciano a produrre output sempre più deteriorati e privi di valore. Il recente studio di Ilia Shumailov e dei suoi colleghi ha dimostrato che, nel giro di poche generazioni, i contenuti originali possono essere rapidamente sostituiti da informazioni senza senso o irrilevanti.
Questo fenomeno è stato osservato chiaramente nei test condotti dagli autori, dove un modello, inizialmente addestrato su testi di architettura medievale, ha cominciato a generare frasi prive di significato, come una lista di conigli, già dalla nona generazione. Gli studiosi hanno sviluppato modelli matematici per spiegare come e perché questo collasso avvenga. La chiave del problema risiede nel fatto che i modelli di IA possono trascurare alcuni output nei loro dati di formazione, concentrandosi solo su una parte del dataset che diventa dominante nel ciclo ricorsivo.
Questo porta a una progressiva degradazione delle capacità del modello di apprendere e generare contenuti pertinenti e utili. L’analisi ha rivelato che la ripetizione e la qualità dei dati generati tendono a peggiorare nel tempo, con effetti deleteri sulla capacità complessiva del modello di produrre output di valore.
Implicazioni e conseguenze
Le implicazioni di questo fenomeno sono profonde e potenzialmente devastanti per l’industria della IA. Il collasso del modello non solo compromette la qualità delle generazioni future, ma solleva anche interrogativi sull’affidabilità e sull’efficacia dei modelli di IA addestrati su dati generati da IA. Se le aziende e i ricercatori non prestano attenzione a questi effetti collaterali, rischiano di creare sistemi di IA che, a lungo andare, producono contenuti sempre più degradati e inutilizzabili.
La proliferazione di modelli che falliscono nel mantenere standard di qualità potrebbe avere ripercussioni significative in ambiti critici, come la medicina, la giustizia e la consulenza aziendale, dove l’affidabilità dei risultati generati è essenziale. Inoltre, la perdita di fiducia nei sistemi di IA potrebbe ostacolare l’adozione e il progresso in molteplici settori, minando i benefici che la tecnologia potrebbe apportare. È cruciale che le aziende e i ricercatori si impegnino a comprendere e mitigare i rischi associati al collasso del modello per preservare l’integrità e l’efficacia delle soluzioni basate su IA.
Un futuro con dati affidabili
Nonostante le sfide evidenziate dallo studio, gli esperti concordano sul fatto che non è impossibile formare modelli di IA utilizzando dati generati da IA, a patto che si adottino misure adeguate per monitorare e filtrare questi dati. Le aziende tecnologiche che continuano a investire in contenuti generati dall’uomo potrebbero avere un vantaggio competitivo, riuscendo a creare modelli di IA più robusti e affidabili.
Ad esempio, l’implementazione di tecniche di filtro e verifica dei dati, così come l’uso di metodologie di addestramento più sofisticate, possono contribuire a mantenere la qualità dei modelli di IA anche quando si fa uso di dati generati da IA. Inoltre, la collaborazione tra esperti di IA e comunità accademiche può portare a sviluppi innovativi che riducono il rischio di collasso del modello, favorendo la creazione di tecnologie più avanzate e sostenibili. In conclusione, il fenomeno del collasso del modello è un campanello d’allarme per la comunità scientifica e per le industrie che fanno largo uso di modelli di IA.
Per garantire un futuro in cui l’IA continui a servire come strumento potente e utile, è cruciale che si affrontino queste problematiche con serietà e attenzione, mantenendo l’accento sull’importanza di dati di alta qualità e metodi di addestramento adeguati. La consapevolezza e la preparazione in merito a questi rischi possono contribuire a plasmare un futuro in cui la IA rimane un alleato prezioso e affidabile nella nostra società.








